Input¶
Simple Active Learning reads all options from an input file, described here. You can also set up this input file in Python.
Block |
Required? |
Comment |
|---|---|---|
System/LoadSystem |
Yes |
identical to AMS Driver System/LoadSystem |
Task |
No |
must be set to MolecularDynamics |
MolecularDynamics |
Yes |
identical to AMS Driver MolecularDynamics |
Constraints |
No |
identical to AMS Driver Constraints |
RNGSeed |
No |
Random number seed(s) for MD simulations |
Engine |
Yes |
reference engine settings, identical to normal AMS calculations |
MachineLearning |
Yes |
identical to ParAMS MachineLearning settings |
ParallelLevels |
No |
identical to ParAMS ParallelLevels settings |
ActiveLearning |
Yes |
described on this page |
The engine settings for the MD simulations are determined from the MachineLearning input. For example, if you train an M3GNet model, this means that you will automatically run M3GNet also during the MD simulation.
This section only describes the ActiveLearning input block, which controls
How to generate/load initial reference data
When to perform reference calculations
Criteria for deciding whether to retrain the model or continue the MD simulation
How much output to save
Whether to retrain the model and/or rerun the simulation after the active learning loop has finished
See also
Overview¶
ActiveLearning
AtEnd
RerunSimulation Yes/No
RetrainModel Yes/No
End
FromScratchTraining
Enabled Yes/No
EpochMultiplier float
Probability float
End
InitialReferenceData
Generate
M3GNetShortMD
Enabled Yes/No
End
ReferenceMD
Enabled Yes/No
End
End
Load
Directory string
FromPreviousModel Yes/No
End
End
JobPrefix string
MaxAttemptsPerStep integer
MaxReferenceCalculationsPerAttempt integer
ReasonableSimulationCriteria
Distance
Enabled Yes/No
MinValue float
End
EnergyUncertainty
Enabled Yes/No
MaxValue float
Normalization float
End
GradientsUncertainty
Enabled Yes/No
MaxValue float
End
Temperature
Enabled Yes/No
MaxValue float
End
End
Save
ReferenceCalculations [None | All]
ReferenceData [Latest | All]
TrainingDirectories [Latest | All]
Trajectories [Latest | All]
End
Steps
Geometric
NumSteps integer
Start integer
End
Linear
Start integer
StepSize integer
End
List integer_list
Type [Geometric | List | Linear]
End
SuccessCriteria
Energy
Enabled Yes/No
Normalization float
Relative float
Total float
End
Forces
Enabled Yes/No
MaxDeviationForZeroForce float
MaxMAE float
MinR2 float
End
End
End
Initial reference data¶
Before the main active learning loop starts, there must be some training data.
The initial training data can be loaded from disk and/or automatically
generated. If no data is loaded and no generation option is explicitly enabled,
then the ReferenceMD option described below will be automatically enabled
to ensure that there is some data for the initial model training.
ActiveLearning
InitialReferenceData
Generate
M3GNetShortMD
Enabled Yes/No
End
ReferenceMD
Enabled Yes/No
End
End
Load
Directory string
FromPreviousModel Yes/No
End
End
End
Generate initial reference data¶
The M3GNetShortMD option (recommended) follows a short pre-programmed MD simulation using the universal M3GNet-UP-2022 potential. This gives some structural variation in the initial training data. It generates structures as follows:
300 MD steps with timestep 0.5 fs, temperature = 500 K
If the system is 3d-periodic then linearly scale the density from 92% to 108% of the original density
5 frames are recalculated with the reference engine and added to the training/validation sets
The ReferenceMD option (default if nothing else is specified)
Runs 3 MD steps (saving every frame) using the exact MolecularDynamics settings specified in the input
Adds those frames to the training/validation sets
Load initial reference data¶
If you already have some reference data, for example if you have
previously run Simple Active Learning, or
manually created the data by importing into ParAMS and saving,
then you can load it in Simple Active Learning, so that the old data is combined with the new data generated during the workflow.
If you specify the ActiveLearning%InitialReferenceData%Load%Directory option, then the initial reference
data will be taken from that directory.
Otherwise, if you’re loading a previously trained model using
MachineLearning%LoadModel, and if you
enable ActiveLearning%InitialReferenceData%Load%FromPreviousModel, then both
the parameters and the training and validation data will be loaded.
Initial reference data input¶
ActiveLearning- Type:
Block
- Description:
Settings for Active Learning
InitialReferenceData- Type:
Block
- Description:
Options for loading reference data.
Generate- Type:
Block
- Description:
How to generate initial reference data from the initial structure. Can also be combined with the
Loadblock. The purpose of these options is to get some initial reference structures/data around the current structure that can be used for Step 1 of the active learning loop. TheReferenceMDoption will be automatically enabled if no data is otherwise loaded or generated.
M3GNetShortMD- Type:
Block
- Description:
Structure sampler using M3GNet-UP-2022
Enabled- Type:
Bool
- Default value:
No
- GUI name:
M3GNet-UP short MD:
- Description:
Run 300 steps with M3GNet-UP-2022 at T=600 K. If the system is 3D-periodic the density will be scanned around the initial value. Extract 5 frames and run reference calculations on those.
ReferenceMD- Type:
Block
- Description:
Run a very short MD simulation using the reference engine.
Enabled- Type:
Bool
- Default value:
No
- GUI name:
Reference MD:
- Description:
Run 3 steps with the reference engine and add those 3 frames to the training and validation sets. If no other reference data is loaded or generated, this option will automatically be enabled.
Load- Type:
Block
- Description:
How to load initial reference data from other sources. Can also be combined with the
Generateblock
Directory- Type:
String
- Default value:
- Description:
Directory containing initial reference data. It can be * a ParAMS input directory or a
stepX_attemptY_reference_datadirectory containing the files job_collection.yaml, training_set.yaml, and validation_set.yaml. * a ParAMS results directory. If a directory is specified here it will be used instead of the data from a previously loaded model.
FromPreviousModel- Type:
Bool
- Default value:
Yes
- Description:
If
MachineLearning%LoadModelis set, reuse reference data from that ParAMS run. IfMachineLearning%LoadModelis not set, or ifDirectoryis specified, then this input option is ignored.
When to run reference calculations (step sequence type)¶
In the Simple Active Learning workflow, the MD simulation is divided into a sequence of active learning (AL) steps.
ActiveLearning
Steps
Geometric
NumSteps integer
Start integer
End
Linear
Start integer
StepSize integer
End
List integer_list
Type [Geometric | List | Linear]
End
MaxAttemptsPerStep integer
MaxReferenceCalculationsPerAttempt integer
JobPrefix string
End
Step Type Geometric (default)¶
Example:
You set up the MD simulation with NMD = 10000 steps with a time step of 0.5 fs, giving a total simulation length of 10000*0.5 = 5000 fs = 5 ps.
You set up the ActiveLearning with
Steps%Type = GeometricwithStartset to 10 (MD frames) andNumStepsset to 5, andMaxAttemptsPerStepset to 8
For example using the following input:
MolecularDynamics
NSteps 10000
TimeStep 0.5
# ... other MD options
End
ActiveLearning
Steps
Type Geometric # default
Geometric
Start 10 # default
NumSteps 5
End
End
MaxAttemptsPerStep 8
MaxReferenceCalculationsPerAttempt 4
# ... other ActiveLearning options
End
This will divide the 10000 MD steps into 5 AL steps, where the first AL step
contains 10 MD steps, and each subsequent AL step contains progressively
more MD steps (following a Geometric progression):
The ACTIVE LEARNING loop will contain 5 steps, using the following scheme:
Active Learning Step 1: 10 MD Steps (cumulative: 10)
Active Learning Step 2: 46 MD Steps (cumulative: 56)
Active Learning Step 3: 260 MD Steps (cumulative: 316)
Active Learning Step 4: 1462 MD Steps (cumulative: 1778)
Active Learning Step 5: 8222 MD Steps (cumulative: 10000)
Total number of MD Steps: 10000
Max attempts per active learning step: 8
The progression is geometric because 56/10 ≈ 316/56 ≈ 1778/316 ≈ 10000/1778 ≈ 5.6.
The above scheme means that the active learning loop will be executed as follows:
step1_attempt1_simulation: Run 10 MD steps using the initially trained modelstep1_attempt1_ref_calc1: Run reference calculation on final frameEvaluate the Success criteria:
If no success: run up to 3 more reference calculations, retrain the model, and loop back to the beginning of the step ↰: rerun AL step 1 (the first 10 MD steps) as
step1_attempt2_simulationusing the new parameters, run reference calculation on final frame, evaluate the success criteria, …If success or if the number of attempts >
8: continue to AL step 2
step2_attempt1_simulation: Run 46 MD steps starting from the final frame of AL step 1, for a total (cumulative) length of 56 MD stepsstep2_attempt1_ref_calc1: Run reference calculation on final frameEvaluate the Success criteria:
If no success: run up to 3 more reference calculations, retrain the model, and loop back to the beginning of the step ↰: rerun AL step 2 (the 46 MD steps) as
step2_attempt2_simulationusing the new parameters, run reference calculation on final frame, evaluate the success criteria, …If success or if the number of attempts >
8: continue to AL step 3
step3_attempt1_simulation: Run 260 MD steps starting from the final frame of AL step 2, for a total (cumulative) length of 315 MD stepsEtcetera….
Step Type Linear¶
The steps can also follow a linear progression.
This is especially useful if you run non-equilibrium MD where you linearly apply some restraint, for example if you use a ReactionBoost RMSDRestraint following the TargetCoordinate, or apply a linear lattice deformation.
Instead of providing the number of steps, you provide the start step and the step size:
MolecularDynamics
NSteps 10000
# other MD options...
End
ActiveLearning
Steps
Type Linear
Linear
Start 100
StepSize 2000
End
End
End
Active Learning Step 1: 100 MD Steps (cumulative: 100)
Active Learning Step 2: 2000 MD Steps (cumulative: 2100)
Active Learning Step 3: 2000 MD Steps (cumulative: 4100)
Active Learning Step 4: 2000 MD Steps (cumulative: 6100)
Active Learning Step 5: 2000 MD Steps (cumulative: 8100)
Active Learning Step 6: 1900 MD Steps (cumulative: 10000)
Step Type List¶
You can also list the (cumulative) number of MD steps per active learning step explicitly. The final MD step is always considered to be the end of an active learning step and does not need to be specified.
MolecularDynamics
NSteps 10000
# other MD options...
End
ActiveLearning
Steps
Type List
List 100 3333 4567 7777
End
End
Active Learning Step 1: 100 MD Steps (cumulative: 100)
Active Learning Step 2: 3233 MD Steps (cumulative: 3333)
Active Learning Step 3: 1234 MD Steps (cumulative: 4567)
Active Learning Step 4: 3210 MD Steps (cumulative: 7777)
Active Learning Step 5: 2223 MD Steps (cumulative: 10000)
Steps input¶
ActiveLearning
Steps
Geometric
NumSteps integer
Start integer
End
Linear
Start integer
StepSize integer
End
List integer_list
Type [Geometric | List | Linear]
End
MaxAttemptsPerStep integer
MaxReferenceCalculationsPerAttempt integer
JobPrefix string
End
ActiveLearning- Type:
Block
- Description:
Settings for Active Learning
Steps- Type:
Block
- Description:
Settings to determine the number of MD steps per active learning step.
Geometric- Type:
Block
- Description:
Options for geometric.
NumSteps- Type:
Integer
- Default value:
10
- Description:
The number of active learning steps to perform. The MD simulation will be split into this number of active learning steps. The active learning steps will progressively contain more and more MD steps.
Start- Type:
Integer
- Default value:
10
- Description:
The length of the first step (in MD time steps).
Linear- Type:
Block
- Description:
Options for linear.
Start- Type:
Integer
- Default value:
10
- Description:
The length of the first step (in MD time steps).
StepSize- Type:
Integer
- Default value:
1000
- Description:
The length of every subsequent active learning step (in MD time steps).
List- Type:
Integer List
- Description:
List of MD frame indices, for example
10 50 200 1000 10000 100000. Only indices smaller thanMolecularDynamics%NStepsare considered. Note: the final frame of the MD simulation is always considered to be the end of a step and does not need to be specified here.
Type- Type:
Multiple Choice
- Default value:
Geometric
- Options:
[Geometric, List, Linear]
- GUI name:
Step sequence type:
- Description:
How to determine the number of MD steps per active learning step.
MaxAttemptsPerStep- Type:
Integer
- Default value:
15
- Description:
Maximum number of attempts per active learning step. If this number is exceeded, the active learning will continue to the next step even if the potential is not accurate enough according to the criteria. If the default value is exceeded, it probably means that the criteria are too strict.
MaxReferenceCalculationsPerAttempt- Type:
Integer
- Default value:
4
- GUI name:
Max ref calcs per attempt:
- Description:
Maximum number of reference calculations per attempt. For successful attempts, only a single reference calculation is performed. For very short active learning steps, fewer calculations are done than the number specified.
JobPrefix- Type:
String
- Default value:
- Description:
Jobs added to the job collection will receive this prefix. Example: set to
water_to get jobs likewater_step1_attempt1_frame001. If the prefix does not end with an underscore_, one will be automatically added.
Success criteria¶
At the end of an active learning step, a reference calculation
(stepX_attemptY_ref_calc1) is performed on the last frame of the MD
simulation.
The results (energy and forces) from this reference calculation are compared to the results of the trained ML potential.
Only if the agreement is accurate enough, such that all success criteria are fulfilled, will the Active Learning workflow continue to the next Active Learning Step.
Energy: total and relative¶
Enable the energy success checker with ActiveLearning%SuccessCriteria%Energy%Enabled.
Energies can optionally be normalized by some number before making the
comparison, by specifying the
ActiveLearning%SuccessCriteria%Energy%Normalization input option.
By default energies are normalized by the number of atoms. This is suitable for reasonably homogeneous systems and means that the same criteria can be used for any number of atoms.
You may consider changing the Normalization if your system is very
inhomogeneous, for example if you’re looking at single atom diffusing in a
large bulk crystal.
Total energy¶
The ActiveLearning%SuccessCriteria%Energy%Total compares the ML-predicted energy Epred directly to the reference energy Eref:
ΔE = Epred - Eref
Success if |ΔE|/
Normalization<ActiveLearning%SuccessCriteria%Energy%Total
Relative energy¶
Compare the difference between calculated relative reference energies and relative predicted energies.
This success criterion is not invoked for step1_attempt1 but for all subsequent steps and attempts.
ΔEref = Erefcurrent - Erefprevious
ΔEpred = Epredcurrent - Epredprevious
ΔΔE = ΔEpred - ΔEref
Success if |ΔΔE|/
Normalization<ActiveLearning%SuccessCriteria%Energy%Relative
Forces (gradients)¶
Enable the forces success criterion with ActiveLearning%SuccessCriteria%Forces%Enabled.
The predicted forces are compared to the reference forces in three ways:
Mean absolute error (MAE) in eV/angstrom,
MaxMAER² in the correlation plot between reference and predicted values,
MinR2Maximum deviation,
MaxDeviationForZeroForce
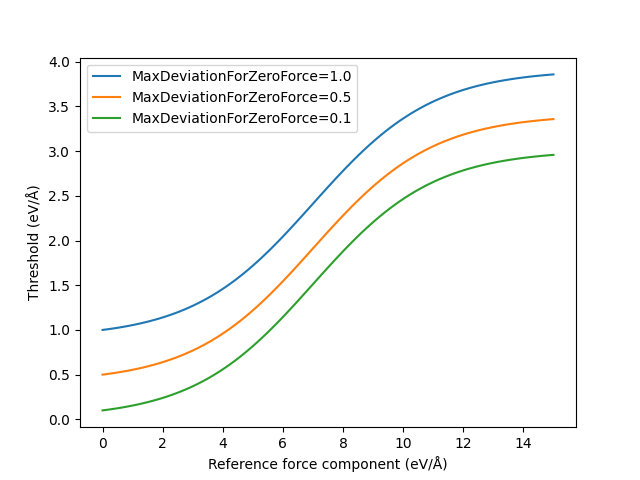
For structures with large components, it is usually not so important the the forces are predicted very accurately, as they represent unstable structures that are unlikely to appear in an MD simulation. For large force components, one can accept a larger error (deviation) between the reference and predicted values.
For this reason, the maximum deviation criterion depends on the magnitude of the reference force. The maximum allowed deviation between predicted and reference force components is determined by the following equation:
where \(y\) is the threshold, \(x\) is the reference force, \(y_0\) is MaxDeviationForZeroForce, \(L\) = 3, \(x_0\) = 7, and \(k\) = 0.5.
There is no theoretical basis for this equation other than that it in practice seems to give reasonable thresholds.
This gives the following calculated threshold vs. reference force for a few different values of MaxDeviationForZeroForce:
Success criteria input¶
ActiveLearning
SuccessCriteria
Energy
Enabled Yes/No
Normalization float
Relative float
Total float
End
Forces
Enabled Yes/No
MaxDeviationForZeroForce float
MaxMAE float
MinR2 float
End
End
End
ActiveLearning- Type:
Block
- Description:
Settings for Active Learning
SuccessCriteria- Type:
Block
- Description:
Criteria for determining whether an active learning step was successful. These criteria compare one or more reference calculations to the predictions. If any of the criteria are exceeded, the active learning loop will reparametrize the model and repeat the step.
Energy- Type:
Block
- Description:
Conditions to decide whether the calculated energy is are accurate enough with respect to reference energies.
Enabled- Type:
Bool
- Default value:
Yes
- Description:
Enable energy checking during the active learning.
Normalization- Type:
Float
- Description:
Normalize (divide) energies by this number before comparing to the specified thresholds. If not specified, it will become the number of atoms.
Relative- Type:
Float
- Default value:
0.005
- Unit:
eV
- GUI name:
Relative energy:
- Description:
|ΔΔE|/Normalization: Maximum allowed difference between the calculated relative reference energies and relative predicted energies. The relative energies are calculated for the current structure with respect to the structure in the previous reference calculation. ΔE_ref = E_ref(current) - E_ref(previous). ΔE_pred = E_pred(current) - E_pred(previous).|ΔΔE| = |ΔE_pred - ΔE_ref|
Total- Type:
Float
- Default value:
0.2
- Unit:
eV
- GUI name:
Total energy:
- Description:
|ΔE|/Normalization: Maximum allowed total energy difference between the reference and predicted energy. This criterion is mostly useful when restarting a workflow from a previously trained model but on a new stoichiometry / system, for which the total energy prediction may be very far from the target. The default value is quite large so it is normally not exceeded.|∆E| = |E_pred - E_ref|
Forces- Type:
Block
- Description:
Conditions to decide whether calculated forces are accurate enough with respect to reference forces.
Enabled- Type:
Bool
- Default value:
Yes
- Description:
Enable checking the forces during the active learning.
MaxDeviationForZeroForce- Type:
Float
- Default value:
0.5
- Unit:
eV/angstrom
- Description:
The maximum allowed deviation between a calculated force component and the corresponding reference force component. For larger reference forces, the allowed deviation will also be larger (see the documentation). If any deviation is larger than the (magnitude-dependent) threshold, the active learning step will be repeated after a reparametrization.
MaxMAE- Type:
Float
- Default value:
0.3
- Unit:
eV/angstrom
- GUI name:
Max MAE:
- Description:
Maximum allowed mean absolute error when comparing reference and predicted forces for a single frame at the end of an active learning step. If the obtained MAE is larger than this threshold, the active learning step will be repeated after a reparametrization.
MinR2- Type:
Float
- Default value:
0.2
- GUI name:
Min R²:
- Description:
Minimum allowed value for R^2 when comparing reference and predicted forces for a single frame at the end of an active learning step. If the obtained R^2 is smaller than this threshold, the active learning step will be repeated after a reparametrization. Note that if you have very small forces (for example by running the active learning at a very low temperature or starting from a geometry-optimized structure), then you should decrease the MinR2 since it is difficult for the ML model predict very small forces accurately.
Reasonable simulation criteria (uncertainties, temperature, …)¶
When running MD simulations with ML potentials, it may happen that the simulation explores configurational space where the ML potential was not trained.
This can lead to strange behavior like
atoms crashing into each other
extremely high temperatures
The active learning workflow will try to detect these events and discard any subsequent structures.
If you train a ParAMS ML Committee (MachineLearning%CommitteeSize > 1), the
ML model will also return an estimated uncertainty of predicted energies and
forces.
You can also set a threshold for these uncertainties, such that if they are exceeded the MD simulation immediately stops, even before the end of the active learning step. You can thus choose to use the predicted uncertainties to decide when to stop the simulation, and use structures with high uncertainty for the training set. This method can be used in addition to active learning step division.
Criterion |
Implementation |
Temperature |
inside active learning workflow |
Distance |
AMS Exit Condition |
Energy uncertainty |
AMS Exit Condition |
Forces uncertainty |
AMS Exit Condition |
Note
If a “reasonable simulation criterion” is exceeded, this will never count as a successful step/attempt.
It will always lead to a retraining of the model and an increase of the attempt number, even if MaxAttemptsPerStep is exceeded.
ActiveLearning
ReasonableSimulationCriteria
Distance
Enabled Yes/No
MinValue float
End
EnergyUncertainty
Enabled Yes/No
MaxValue float
Normalization float
End
GradientsUncertainty
Enabled Yes/No
MaxValue float
End
Temperature
Enabled Yes/No
MaxValue float
End
End
End
ActiveLearning- Type:
Block
- Description:
Settings for Active Learning
ReasonableSimulationCriteria- Type:
Block
- Description:
Criteria for determining whether a simulation is reasonable. If any of the criteria are exceeded, this will be reported as ‘ENERGY_UNCERTAINTY’, ‘TEMPERATURE’, etc., with capital letters in the output. If a simulation is unreasonable, it will never lead to an increase of the Step, even if the number of attempts exceeds
MaxAttemptsPerStep.
Distance- Type:
Block
- Description:
Stop the simulation if any interatomic distance is smaller than the specified value.
Enabled- Type:
Bool
- Default value:
Yes
- Description:
Stop the simulation if any interatomic distance is smaller than the specified value.
MinValue- Type:
Float
- Default value:
0.6
- Unit:
angstrom
- GUI name:
Minimum
- Description:
Minimum allowed interatomic distance.
EnergyUncertainty- Type:
Block
- Description:
Stop the simulation if the uncertainty in the energy is too high. Currently only applicable when training committees.
Enabled- Type:
Bool
- Default value:
No
- Description:
Stop the simulation if the uncertainty in the energy is too high. Currently only applicable when training committees. If CommitteeSize = 1 then this keyword has no effect.
MaxValue- Type:
Float
- Default value:
0.015
- Unit:
eV
- GUI name:
Maximum
- Description:
Threshold for allowed [energy uncertainty divided by
Normalization].
Normalization- Type:
Float
- Description:
Normalize (divide) the energy uncertainty by this number before comparing to the specified threshold. If not specified, it will become the number of atoms.
GradientsUncertainty- Type:
Block
- Description:
Stop the simulation if the uncertainty in the gradients (forces) is too high. Currently only applicable when training committees.
Enabled- Type:
Bool
- Default value:
No
- Description:
Stop the simulation if the uncertainty in the gradients (forces) is too high. Currently only applicable when training committees. If CommitteeSize = 1 then this keyword has no effect.
MaxValue- Type:
Float
- Default value:
0.5
- Unit:
eV/angstrom
- GUI name:
Maximum
- Description:
Maximum allowed gradients (forces) uncertainty.
Temperature- Type:
Block
- Description:
Discard all frames after the temperature has reached the specified value.
Enabled- Type:
Bool
- Default value:
Yes
- Description:
Discard all frames after the temperature has reached the specified value.
MaxValue- Type:
Float
- Default value:
5000.0
- Unit:
K
- GUI name:
Maximum
- Description:
Maximum allowed temperature
From scratch training¶
By default, ParAMS will reuse the parameters from the previous step/attempt as a starting point for the parametrization. Sometimes, this means that the optimizer gets stuck in a local minimum that is good for the structures encountered early in the simulation, but not for later ones.
By enabling FromScratchTraining, the optimization can be made to start from the
original parameters with a given probability. Here the “original parameters”
refers to what you would get if there was no LoadModel provided in the
MachineLearning input block.
ActiveLearning
FromScratchTraining
Enabled Yes/No
EpochMultiplier float
Probability float
End
End
ActiveLearning- Type:
Block
- Description:
Settings for Active Learning
FromScratchTraining- Type:
Block
- Description:
Custom options when training ‘from scratch’ (not restarting).
Enabled- Type:
Bool
- Default value:
No
- Description:
With the given probability, start parameter training from the original starting point (from ‘scratch’) instead of restarting from the previous step/attempt.
EpochMultiplier- Type:
Float
- Default value:
5.0
- Description:
The maximum number of epochs is multiplier by this number when training from scratch. When not restarting from the previous parameters, it is usually a good idea to train for more epochs.
Probability- Type:
Float
- Default value:
0.1
- Description:
With the given probability, start parameter training from the original starting point (from ‘scratch’) instead of restarting from the previous step/attempt.
Output to save¶
The active learning workflow produces many directories containing reference calculations, MD simulations, and ParAMS training. You can choose how much output to save.
By default, the workflow only keeps the directories it needs to keep going. This always includes
the entire training and validation sets, and
the MD trajectory from the beginning of the workflow.
By default, the reference calculation directories are not saved unless the reference calculation fails.
ActiveLearning
Save
ReferenceCalculations [None | All]
ReferenceData [Latest | All]
TrainingDirectories [Latest | All]
Trajectories [Latest | All]
End
End
ActiveLearning- Type:
Block
- Description:
Settings for Active Learning
Save- Type:
Block
- Description:
The files/directories on disk to keep. If you set these options to
All, a lot of output will be created. This output is usually not necessary but can be used for debugging purposes, or to better understand what the workflow is doing.
ReferenceCalculations- Type:
Multiple Choice
- Default value:
None
- Options:
[None, All]
- Description:
The reference calculation directories (
initial_reference_calculationsorstepX_attemptY_ref_calcZ) including the original input and output. These directories may take up a lot of disk space and are not kept by default. Enable this option if you need to investigate why reference calculations fail (incorrect input, SCF convergence problems, …), or if you want to keep them for some other reason. Note: The output used for parametrization (energy, forces) is always stored in the ReferenceData (training and validation sets).
ReferenceData- Type:
Multiple Choice
- Default value:
Latest
- Options:
[Latest, All]
- Description:
The reference data directories (
stepX_attemptY_reference_data) containing the training and validation sets in ParAMS .yaml format (and ASE .xyz format). These can be opened in the ParAMS GUI or used as input for ParAMS.
TrainingDirectories- Type:
Multiple Choice
- Default value:
Latest
- Options:
[Latest, All]
- Description:
The ParAMS training directories (
stepX_attemptY_training).
Trajectories- Type:
Multiple Choice
- Default value:
Latest
- Options:
[Latest, All]
- Description:
The MD trajectory calculation directories (
stepX_attemptY_simulation) using the trained ML potential. Note: the trajectories in these directories are the entire trajectories from the beginning of the simulation.
At workflow end: retrain model, rerun simulation¶
Retrain model¶
After the final active learning step, you have the option to retrain the model using all reference data.
This may be useful to not “waste” reference calculations that have been performed but not used for training.
Example: if the the last 3 active learning steps are successful at the first attempt, then the workflow will have run 3 reference calculations (for the evaluation of the success criteria) that have not been used for training or validation.
The downside of retraining the model is that you may end up with a model that would have failed the success criteria!
By default, the model is not automatically retrained.
Rerun simulation (final production simulation)¶
After the final active learning step is successful, you can rerun the entire MD simulation from scratch using the final model parameters.
This will give you an MD trajectory with consistent sampling frequency and calculated using a single potential energy surface.
It is run in a directory called final_production_simulation, and replaces
the ams.rkf file in the main results directory.
The reasonable simulation criteria are not applied to the final production simulation.
AtEnd input¶
ActiveLearning
AtEnd
RerunSimulation Yes/No
RetrainModel Yes/No
End
End
ActiveLearning- Type:
Block
- Description:
Settings for Active Learning
AtEnd- Type:
Block
- Description:
What to do at the end of the active learning loop.
RerunSimulation- Type:
Bool
- Default value:
Yes
- Description:
Rerun the MD simulation (folder:
final_production_simulation) using the last set of parameters. This guarantees that the entire trajectory is calculated using the same model / potential energy surface, and that the trajectory has a consistent sampling frequency. This means that it can be used with all MD postanalysis tools.
RetrainModel- Type:
Bool
- Default value:
No
- Description:
Train a final model (folder:
final_training) using all reference (training and validation) data, including any reference calculations that have not yet been trained to.