Parallelism¶
Important
This document is NOT relevant if using ParAMS. In ParAMS the parallelization is handled by Parallel Levels. ParAMS cannot handle using processes the way described below.
Resource balancing is critical to GloMPO’s success. The typical GloMPO execution hierarchy takes the following form:
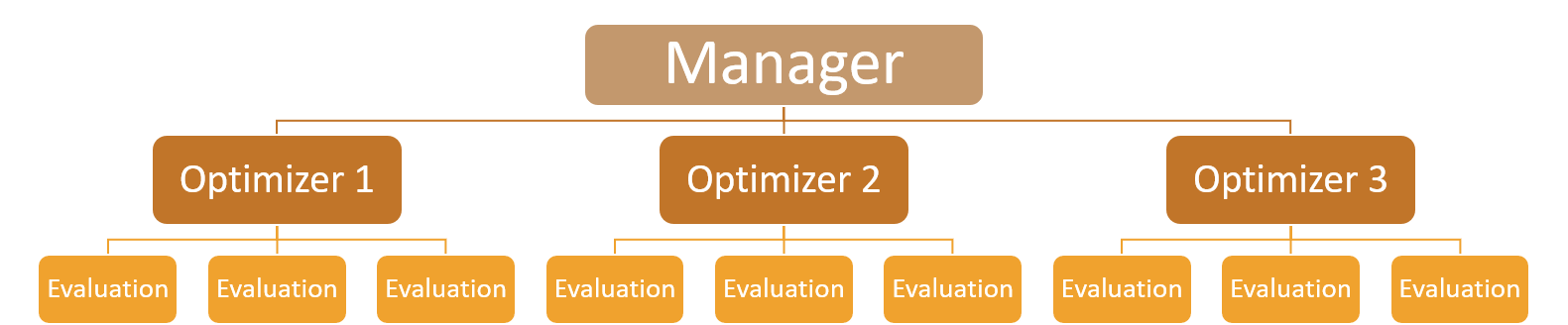
The first level of parallelization is done at the manager level and controls how the optimizer routines are spun off from the manager. This can be done using multiprocessing or multithreading and is controlled by sending 'processes' or 'threads' to the backend parameter of the GloMPOManager initialization method. Processes are preferable to threads as they sidestep the Python Global Interpreter Lock but there are scenarios where this is inappropriate.
The second level of parallelization is optimizer specific and present in swarm type optimizers like CMA-ES which require multiple function evaluations per optimizer iteration. These too can generally be evaluated in parallel using processes or threads. This can be configured by sending 'processes', 'threads' or 'processes_forced' to the backend parameter of BaseOptimizer objects during initialization. To avoid crashes (see table below) GloMPO defaults to threading at this level. Parallelization at this level is not always advisable and should only be used in cases where the function evaluation itself is very expensive.
In the case where the function being minimized is in pure Python (and there are no calls to processes outside of Python or calculations based on I/O calls) then load balancing will become challenging due to Python’s own limitations:
Parallelization |
Setup |
|
|---|---|---|
Level 1 |
Level 2 |
|
Threads |
Threads |
Total lock within a single Python process due to the GIL.
No parallelism can be achieved unless the bulk of the
calculation time is spent in an external subprocess.
|
Threads |
Processes |
Heavy burden on single process to run the manager and
optimizer routines but the load can be adequately
distributed over all available resources if the function
evaluations are slow enough that the single
manager / optimizers process does not become a bottleneck.
|
Processes |
Threads |
Not advisable. Processes are launched for each optimizer
but parallel function evaluations (which should be more
expensive than the optimization routine itself) is
threaded to no benefit due to the GIL.
|
Processes |
Processes |
Theoretically the ideal scenario which guarantees perfect
parallelism and full use of available resources. However,
Python does not allow daemonic processes (optimizers) to
spawn children (parallel function evaluations). Turning
off daemonic spawning of optimizers is risky as it is
possible they will not be cleaned-up if the manager
crashes. GloMPO does, however, do its best to deal with
this eventuality but there are scenarios where children
are not collected.
|
Note
We emphasize here that these difficulties only arise when attempting to load balance over two parallelization levels.
As explained in the table above, achieving process parallelism at both levels is not straightforward, but GloMPO does support an avenue to do this. However, its use is not recommended: the user may send 'processes_forced' to the backend parameter of the GloMPOManager initialization method. This will spawn optimizers non-daemonically.
Warning
This method is not recommended. It is unsafe to spawn non-daemonic processes since these expensive routines will not be shutdown if the manager were to crash. The user would have to terminate them manually.
The appropriateness of each configuration depends on the task itself. Using multiprocessing may provide computational advantages but becomes resource expensive as the task is duplicated between processes. There may also be I/O collisions if the task relies on external files during its calculation.
If threads are used, make sure the task is thread-safe! Also note that forced terminations are not possible in this case and hanging optimizers will not be stopped.
Finally, GloMPO is not configured for use over multiple nodes. It is currently limited to use over a single machine.