5.6. Restarting an optimization¶
You can continue an optimization from where a previous one stopped through the use of checkpoints. Checkpoints are snapshots in time of the optimization. They save to disk: trajectory data for all living optimizers, and their internal states.
This tutorial will show you how to:
setup an optimization with checkpointing;
continue an optimization from a checkpoint file.
This example will use the same problem as Getting Started: Lennard-Jones.
The example files can be found in $AMSHOME/scripting/scm/params/examples/LJ_Ar_restart.
5.6.1. Setting up checkpointing¶
To change checkpointing settings go to the checkpointing panel:
 to open the optimization window
to open the optimization windowThere are various points when one can make checkpoints:
at the start of the optimization (before any optimizers have been spawned);
at the end of the optimization (after the exit condition has triggered but before any optimizers are stopped);
every n function evaluations;
once every n seconds.
You can use the above options in any combination.
Tip
By default ParAMS will build checkpoints after every hour during an optimization.
We will make a checkpoint every 100 function evaluations:
We can also control how many checkpoints are kept.
By default only one checkpoint is kept, with newer ones overwriting older ones. You can retain more to restart further back in time.
We will keep 3 older checkpoints:
Important
The above is all that is needed to setup checkpointing.
The following adjustments we make should normally not be set. We only do this in this tutorial to ensure we get the same sequencing of results for demonstrative purposes.
We begin with the optimizer, we will use a numerical seed in the random number generator:
Important
The optimizers provided by ParAMS are generally compatible with checkpointing. The Scipy optimizer is the only exception due to limitations in the Scipy code.
seed 112We also adjust the settings to make the optimization totally serial:
Finally, we adjust the logging frequency to capture every point:
Save and run the optimization:
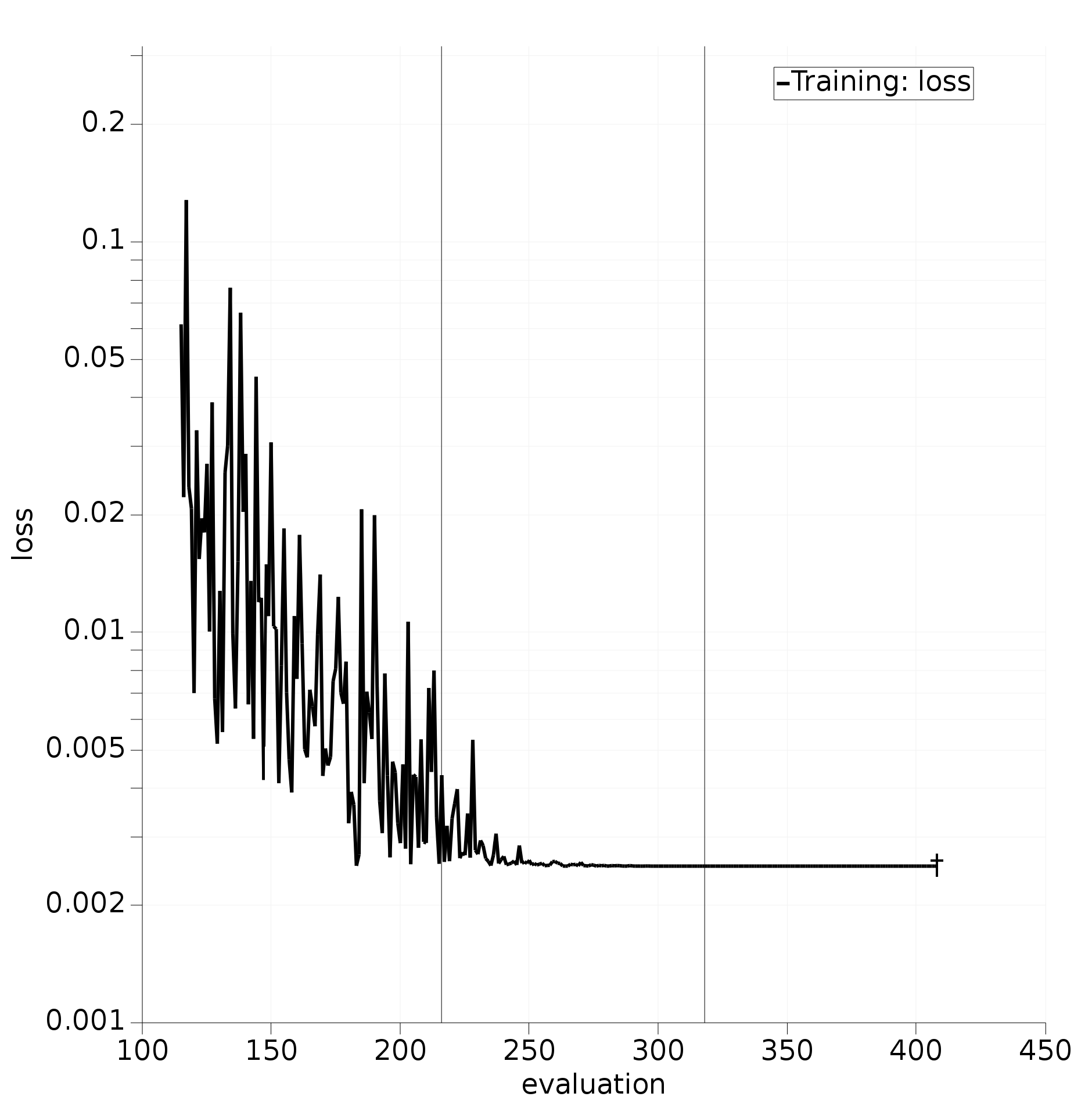
initial.paramsResults will start to develop on the Graphs panel. Black vertical lines are appended to the loss graph to indicate the points where checkpoints have been constructed:
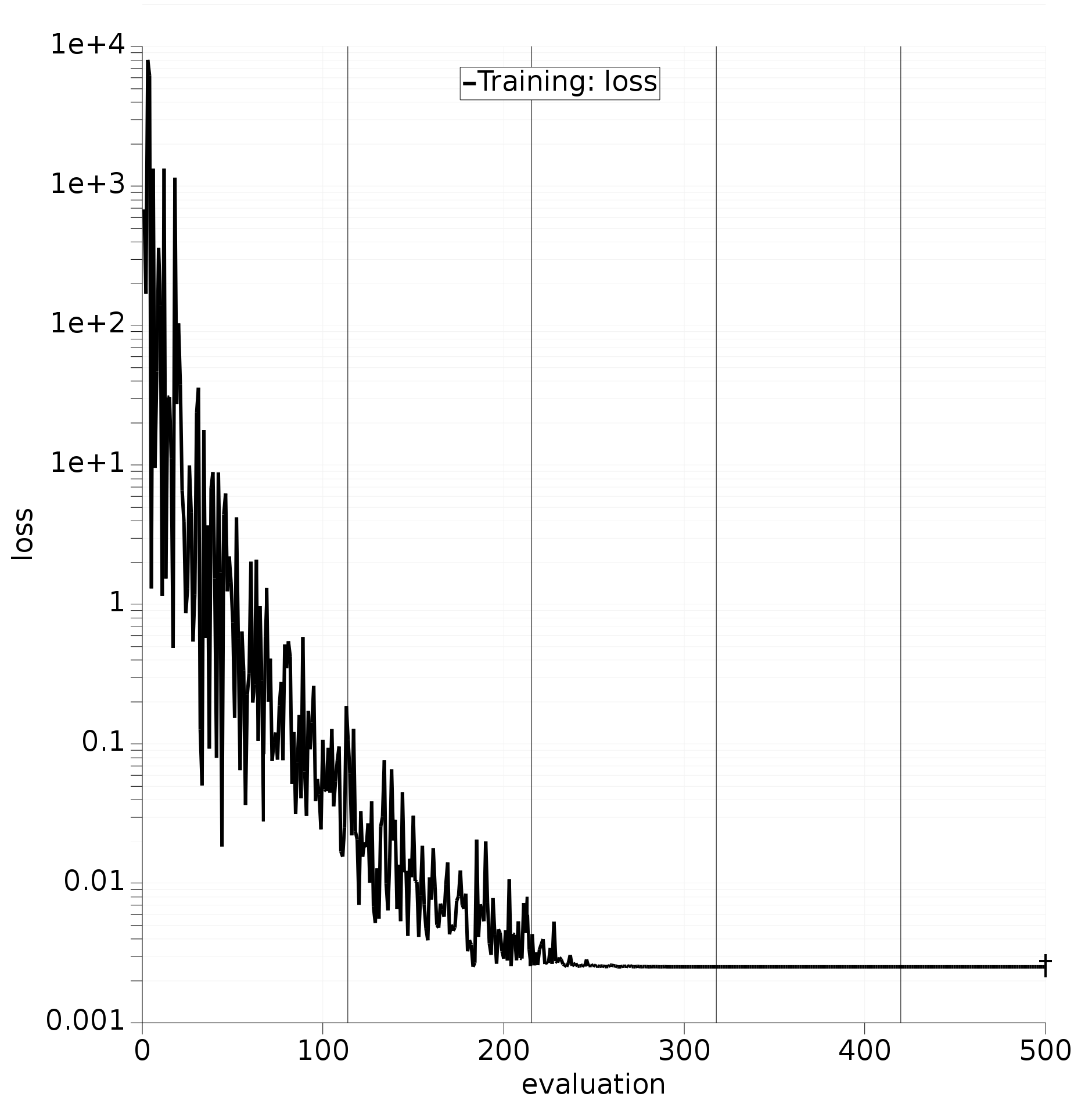
Fig. 5.14 Loss trajectory of the optimizer with vertical black lines showing the points of saved checkpoints.¶
Notice that the lines do not align perfectly with the requested interval of 100 evaluations. This is because some buffer is always needed to pause and sync the optimizers, and process all outstanding results.
Checkpoint files are saved in <jobname>.results/checkpoints.
This folder also contains checkpoints.txt which lists the function evaluations corresponding to each of the checkpoints in the directory.
5.6.2. Restarting from a checkpoint¶
and select Main to navigate to the earliest checkpoint (file ending with .tar.gz) in
to navigate to the earliest checkpoint (file ending with .tar.gz) in <jobname>.results/checkpointsThis is all that is required to resume from a checkpoint.
For a literal restart, do not change any of the other options.
However, you may change any other settings you like, the optimizers will continue as normal but they will operate within the new context.
There are times when this can be useful. Some examples:
changing stopping rules to make them more aggressive;
changing exit conditions to extend an optimization which has not yet converged;
changing training set weights / items to refocus an optimizer’s attention.
Warning
The only changes that are forbidden are those made to the parameter interface, this will result in an error.
For demonstrative purposes we will reduce our exit condition to 400 function evaluations:
Save and run:
Warning
When resuming from a checkpoint you must save to a new job. If you overwrite an existing job this will result in an error.
resume.paramsNotice that as the results appear on the Graphs panel that they start after iteration 100. Also note that the optimization finishes as expected after 400 function evaluations.
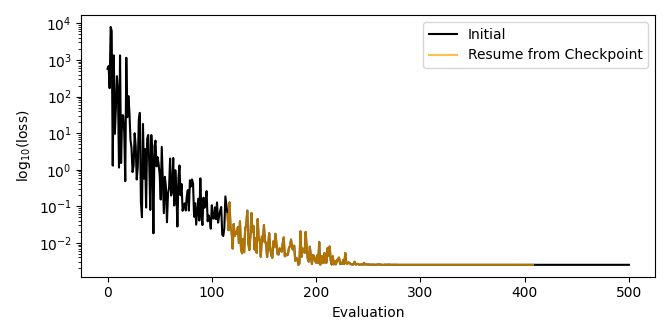
When resuming a checkpoint, results from a previous optimization will not be shown, but the evaluation numbers will be unique and continue from previous results so they can be linked.
For example, in the image below we have plotted together the running_loss.txt files produced by the initial run and the resumed run.
You can see a perfect overlap between them.
5.6.3. Resume from checkpoint with Python¶
See run.py:
#!/usr/bin/env amspython
from scm.plams import *
from scm.params import *
import numpy as np
import os
import matplotlib.pyplot as plt
def main():
init()
inputfile = os.path.expandvars("$AMSHOME/scripting/scm/params/examples/LJ_Ar_restart/params.in")
job = ParAMSJob.from_inputfile(inputfile, name="initial")
job.run()
earliest_checkpoint_file = job.results.get_checkpoints()[0]
restart_job = ParAMSJob.from_inputfile(inputfile, name="resume_from_checkpoint")
restart_job.resume_checkpoint = earliest_checkpoint_file
restart_job.settings.input.ExitCondition = []
restart_job.add_exit_condition("MaxTotalFunctionCalls", 400)
restart_job.run()
evaluation, loss = job.results.get_running_loss()
restart_evaluation, restart_loss = restart_job.results.get_running_loss()
plt.plot(evaluation, np.log10(loss), restart_evaluation, np.log10(restart_loss))
plt.legend(["Initial", "Resume from Checkpoint"])
plt.xlabel("Evaluation id")
plt.ylabel("log10(loss)")
plt.show()
finish()
if __name__ == "__main__":
main()