5.7. Training and validation sets¶
Important
First go through the Getting Started: Lennard-Jones tutorial.
With ParAMS, you can have a validation set in addition to the training set.
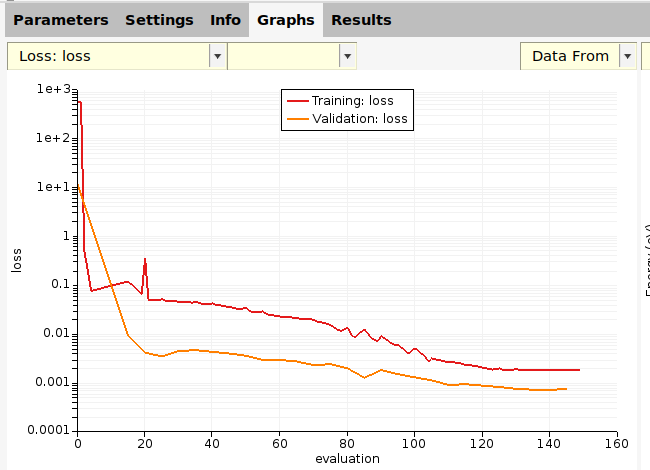
The optimizer will minimize the loss function on the training set. During the parametrization, you can also monitor the loss function on the validation set (see figure above). This approach is used to prevent overfitting. As long as the loss function on the (appropriately chosen) validation set is decreasing similarly to the loss function on the training set, it means that there is likely no overfitting.
The validation set should be stored in validation_set.yaml.
5.7.1. Create a validation set¶
Make a copy of the directory $AMSHOME/scripting/scm/params/examples/LJ_Ar_validation_set.
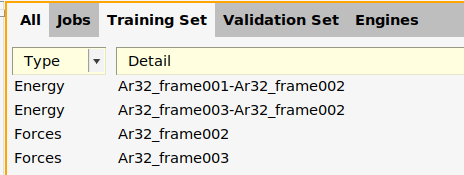
Ar32_frame001.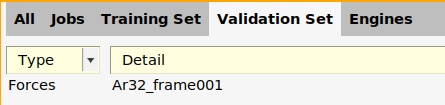
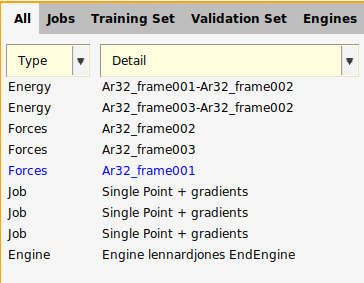
Move an entry from the training set to validation set:
Ar32_frame003.Move an entry from the validation set to training set:
Ar32_frame003.You can also do a random training/validation split on selected entries:
40.0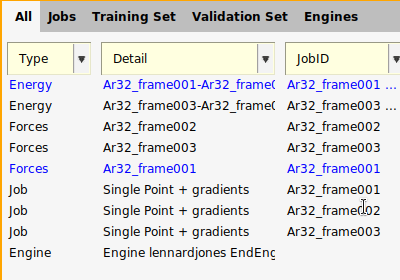
Before continuing, revert all changes:
This places just the forces for the Ar32_frame001 job in the validation set again.
The files are almost identical to the files in the first tutorial. There is a new file, validation_set.yaml, containing a
data set entry with the Expression: forces('Ar32_frame001'). The
corresponding expression has been removed from training_set.yaml.
The below shows how to do a random split of a data set into training and validation sets. The original data set is loaded from the LJ_Ar example.
def data_set_random_split():
# get training set from LJ_Ar example (5 entries)
data_set = DataSet(os.path.expandvars("$AMSHOME/scripting/scm/params/examples/LJ_Ar/training_set.yaml"))
subsets = data_set.split(0.6, 0.4, seed=319)
training_set = subsets[0]
validation_set = subsets[1]
print("Results from random train/validation split:")
print(f"Training set #entries: {len(training_set)}, entries: {training_set.keys()}")
print(f"Validation set #entries: {len(validation_set)}, entries: {validation_set.keys()}")
training_set.store("training_set_from_random_split.yaml")
validation_set.store("validation_set_from_random_split.yaml")
Note
There is only one job collection! It is used for both the training
and validation sets. For example, the job Ar32_frame001 is needed for both the
training and validation sets.
energy('Ar32_frame001')-energy('Ar32_frame002')is part of the training setforces('Ar32_frame001')is part of the validation set
5.7.2. Validation set settings¶
 panel in the bottom half
panel in the bottom half5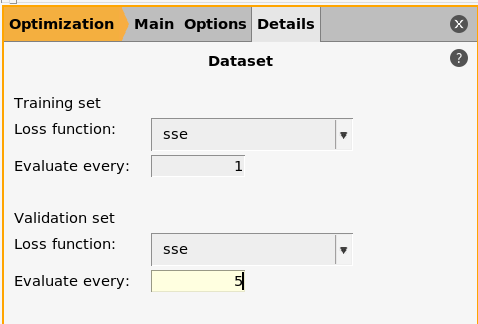
5.The params.in file now references both the training_set.yaml and
validation_set.yaml files.
1DataSet
2 Name training_set
3 Path training_set.yaml
4End
5DataSet
6 Name validation_set
7 Path validation_set.yaml
8End
9
10LoggingInterval
11 General 5
12End
13
14JobCollection job_collection.yaml
15
16Optimizer
17 Scipy
18 Algorithm Nelder-Mead
19 End
20 Type Scipy
21End
22
23ParallelLevels
24 Jobs 1
25 Optimizations 1
26 ParameterVectors 1
27 Processes 1
28 Threads 1
29End
30
31ParameterInterface parameter_interface.yaml
32
33Task Optimization
34
LoggingInterval%General5 means that information about the optimization is logged every 5 iterations (for the training and validation sets)EvaluateEvery5 means that the validation set will only be evaluated every 5 iterations (the training set must by definition be evaluated every iteration).
Tip
We recommend to set EvaluateEvery and LoggingInterval%General to the same value.
If the validation set is very expensive to calculate, set EvaluateEvery to
a multiple of LoggingInterval%General, otherwise the validation error will not
be logged!
5.7.3. Run the optimization¶
In a terminal, run
"$AMSBIN/params"
Use the run.py from the examples directory:
"$AMSBIN/amspython" run.py
5.7.4. Training and validation set results¶
On the Validation Set panel, you can see the predictions and loss contributions just as on the Training Set panel.
On the Graphs panel, you can plot results for the training set, validation set, or both.
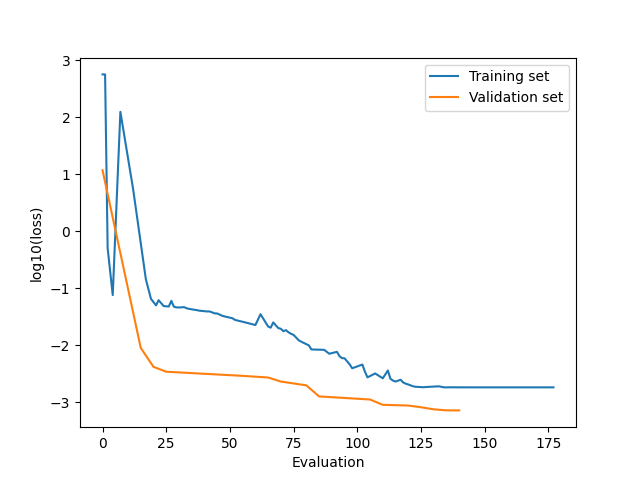
In this case, both the training set and validation set losses decrease, so there is no sign of overfitting.
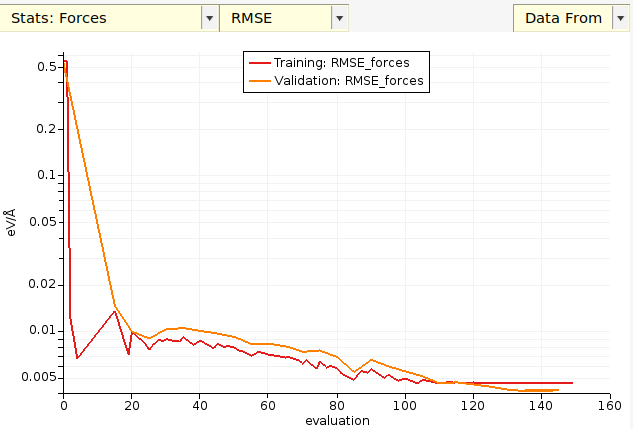
You can also plot the root-mean-squared error (RMSE) or mean absolute error (MAE) as a function of evaluation for both the training and validation sets:
Note
If you plot Stats → Energy then you do not get any validation set results, since there were no Energy entries in the validation set!
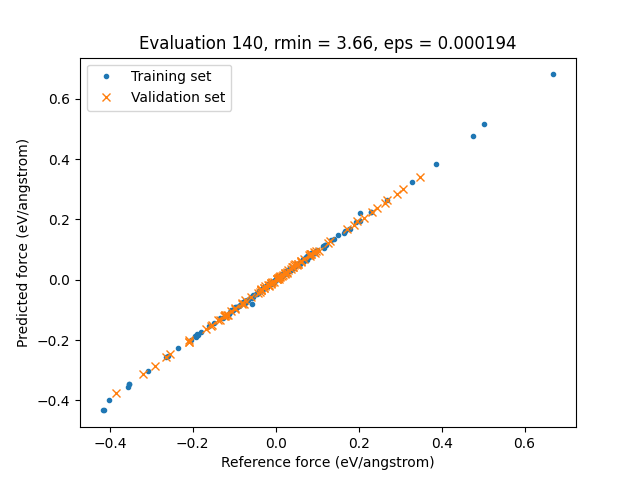
For scatter plots:
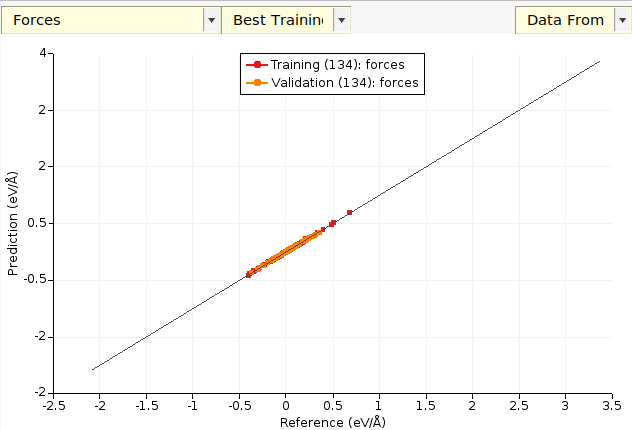
The (134) (in your case the number may be different) indicates the evaluation number the parameters came from. Every set of
parameters during the parametrization has a unique evaluation number.
The default plot is Best Training, which in this case corresponds to the parameters at evaluation 134.
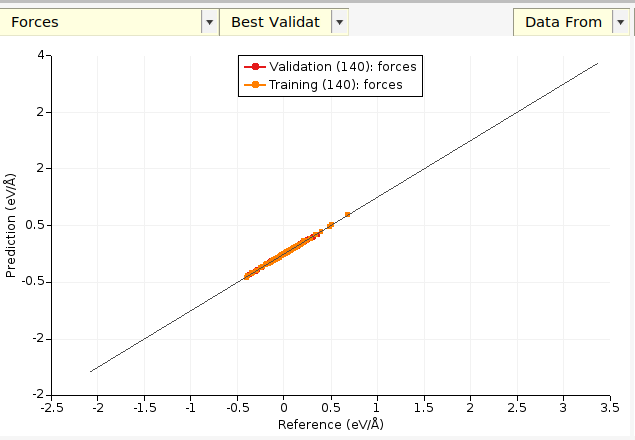
Note
Only after the parametrization has finished (from convergence, max_evaluations, or timeout) will you get the validation set results for the best training set parameters and vice versa. While the parametrization is running you will only be able to plot results for the training set using the best training set parameters, and for the validation set using the best validation set parameters.
You can also plot the latest evaluation:
Here, the latest training set evaluation was done with a different set
of parameters than the latest validation set parameters. This is
because the validation set is only evaluated every 5 iterations (as
specified by the eval_every keyword in the settings).
Tip
You double-click on a plot axis to access plot configuration settings.
The results for the validation set enter a directory called validation_set_results:
settings_and_initial_data/
optimization/
├── summary.txt
├── training_set_results
├── validation_set_results
The layout is exactly the same as for training_set_results.
Important
The validation_set_results/best directory contains results for the parameters that had the lowest validation set loss. This is generally not the same parameters that give the lowest error on the training set (for which the results are in training_set_results/best).
The training_set_results/best and validation_set_results/best directories get updated as the parametrization progresses.
If the parametrization finishes successfully, either from reaching convergence, max total function calls, or the time limit, then two extra “best” directories will be created:
Directory |
Results for |
Parameters gave lowest loss for |
|
training set |
training set |
|
training set |
validation set |
|
validation set |
validation set |
|
validation set |
training set |
The following pairs of files should be identical:
training_set_results/best/parameter_interface.yamlandvalidation_set_results/training_set_best_paramaters/parameter_interface.yamltraining_set_results/best/evaluation.txtandvalidation_set_results/training_set_best_paramaters/evaluation.txtvalidation_set_results/best/parameter_interface.yamlandtraining_set_results/validation_set_best_paramaters/parameter_interface.yamlvalidation_set_results/best/evaluation.txtandtraining_set_results/validation_set_best_paramaters/evaluation.txt
See the tab Output files above for more information about the output files.
The below functions come from run.py.
To plot the running loss:
def running_loss(job):
train_eval, train_loss = job.results.get_running_loss()
val_eval, val_loss = job.results.get_running_loss(data_set="validation_set")
plt.clf()
plt.plot(train_eval, np.log10(train_loss))
plt.plot(val_eval, np.log10(val_loss))
plt.legend(["Training set", "Validation set"])
plt.xlabel("Evaluation")
plt.ylabel("log10(loss)")
plt.savefig("running_loss.png")
To get the predictions for the parameters that gave the lowest error on the validation set:
def predictions_for_best_parameters_on_validation_set(job):
# first sanity-check that the parameter interface in
# results/training_set_results/validation_set_best_parameters and
# results/validation_set_results/best
# are the same
best_val_interf = job.results.get_parameter_interface(source="best", data_set="validation_set")
val_set_best_interf = job.results.get_parameter_interface(
source="validation_set_best_parameters", data_set="training_set"
)
assert best_val_interf == val_set_best_interf
train_forces_results = job.results.get_data_set_evaluator(
source="validation_set_best_parameters", data_set="training_set"
).results["forces"]
val_forces_results = job.results.get_data_set_evaluator(source="best", data_set="validation_set").results["forces"]
eval_id = job.results.get_evaluation_number(source="best", data_set="validation_set")
rmin = best_val_interf["rmin"].value
eps = best_val_interf["eps"].value
title = f"Evaluation {eval_id}, rmin = {rmin:.2f}, eps = {eps:.6f}"
unit = train_forces_results.unit
plt.clf()
plt.title(title)
plt.plot(train_forces_results.reference_values, train_forces_results.predictions, ".")
plt.plot(val_forces_results.reference_values, val_forces_results.predictions, "x")
plt.legend(["Training set", "Validation set"])
plt.xlabel(f"Reference force ({unit})")
plt.ylabel(f"Predicted force ({unit})")
plt.savefig("forces_scatter_plot.png")